|
1 Introduction 2 Ground Rules Building a File System 3 File Systems 4 File Content Data Structure 5 Allocation Cluster Manager 6 Exceptions and Emancipation 7 Base Classes, Testing, and More 8 File Meta Data 9 Native File Class 10 Our File System 11 Allocation Table 12 File System Support Code 13 Initializing the File System 14 Contiguous Files 15 Rebuilding the File System 16 Native File System Support Methods 17 Lookups, Wildcards, and Unicode, Oh My 18 Finishing the File System Class The Init Program 19 Hardware Abstraction and UOS Architecture 20 Init Command Mode 21 Using Our File System 22 Hardware and Device Lists 23 Fun with Stores: Partitions 24 Fun with Stores: RAID 25 Fun with Stores: RAM Disks 26 Init wrap-up The Executive 27 Overview of The Executive 28 Starting the Kernel 29 The Kernel 30 Making a Store Bootable 31 The MMC 32 The HMC 33 Loading the components 34 Using the File Processor 35 Symbols and the SSC 36 The File Processor and Device Management 37 The File Processor and File System Management 38 Finishing Executive Startup Users and Security 39 Introduction to Users and Security 40 More Fun With Stores: File Heaps 41 File Heaps, part 2 42 SysUAF 43 TUser 44 SysUAF API Terminal I/O 45 Shells and UCL 46 UOS API, the Application Side 47 UOS API, the Executive Side 48 I/O Devices 49 Streams 50 Terminal Output Filters 51 The TTerminal Class 52 Handles 53 Putting it All Together 54 Getting Terminal Input 55 QIO 56 Cooking Terminal Input 57 Putting it all together, part 2 58 Quotas and I/O UCL 59 UCL Basics 60 Symbol Substitution 61 Command execution 62 Command execution, part 2 63 Command Abbreviation 64 ASTs 65 Expressions, Part 1 66 Expressions, Part 2: Support code 67 Expressions, part 3: Parsing 68 SYS_GETJPIW and SYS_TRNLNM 69 Expressions, part 4: Evaluation UCL Lexical Functions 70 PROCESS_SCAN 71 PROCESS_SCAN, Part 2 72 TProcess updates 73 Unicode revisted 74 Lexical functions: F$CONTEXT 75 Lexical functions: F$PID 76 Lexical Functions: F$CUNITS 77 Lexical Functions: F$CVSI and F$CVUI 78 UOS Date and Time Formatting 79 Lexical Functions: F$CVTIME 80 LIB_CVTIME 81 Date/Time Contexts 82 SYS_GETTIM, LIB_Get_Timestamp, SYS_ASCTIM, and LIB_SYS_ASCTIM 83 Lexical Functions: F$DELTA_TIME 84 Lexical functions: F$DEVICE 85 SYS_DEVICE_SCAN 86 Lexical functions: F$DIRECTORY 87 Lexical functions: F$EDIT and F$ELEMENT 88 Lexical functions: F$ENVIRONMENT 89 SYS_GETUAI 90 Lexical functions: F$EXTRACT and F$IDENTIFIER 91 LIB_FAO and LIB_FAOL 92 LIB_FAO and LIB_FAOL, part 2 93 Lexical functions: F$FAO 94 File Processing Structures 95 Lexical functions: F$FILE_ATTRIBUTES 96 SYS_DISPLAY 97 Lexical functions: F$GETDVI 98 Parse_GetDVI 99 GetDVI 100 GetDVI, part 2 101 GetDVI, part 3 102 Lexical functions: F$GETJPI 103 GETJPI 104 Lexical functions: F$GETSYI 105 GETSYI 106 Lexical functions: F$INTEGER, F$LENGTH, F$LOCATE, and F$MATCH_WILD 107 Lexical function: F$PARSE 108 FILESCAN 109 SYS_PARSE 110 Lexical Functions: F$MODE, F$PRIVILEGE, and F$PROCESS 111 File Lookup Service 112 Lexical Functions: F$SEARCH 113 SYS_SEARCH 114 F$SETPRV and SYS_SETPRV 115 Lexical Functions: F$STRING, F$TIME, and F$TYPE 116 More on symbols 117 Lexical Functions: F$TRNLNM 118 SYS_TRNLNM, Part 2 119 Lexical functions: F$UNIQUE, F$USER, and F$VERIFY 120 Lexical functions: F$MESSAGE 121 TUOS_File_Wrapper 122 OPEN, CLOSE, and READ system services UCL Commands 123 WRITE 124 Symbol assignment 125 The @ command 126 @ and EXIT 127 CRELNT system service 128 DELLNT system service 129 IF...THEN...ELSE 130 Comments, labels, and GOTO 131 GOSUB and RETURN 132 CALL, SUBROUTINE, and ENDSUBROUTINE 133 ON, SET {NO}ON, and error handling 134 INQUIRE 135 SYS_WRITE Service 136 OPEN 137 CLOSE 138 DELLNM system service 139 READ 140 Command Recall 141 RECALL 142 RUN 143 LIB_RUN 144 The Data Stream Interface 145 Preparing for execution 146 EOJ and LOGOUT 147 SYS_DELPROC and LIB_GET_FOREIGN CUSPs and utilities 148 The I/O Queue 149 Timers 150 Logging in, part one 151 Logging in, part 2 152 System configuration 153 SET NODE utility 154 UUI 155 SETTERM utility 156 SETTERM utility, part 2 157 SETTERM utility, part 3 158 AUTHORIZE utility 159 AUTHORIZE utility, UI 160 AUTHORIZE utility, Access Restrictions 161 AUTHORIZE utility, Part 4 162 AUTHORIZE utility, Reporting 163 AUTHORIZE utility, Part 6 164 Authentication 165 Hashlib 166 Authenticate, Part 7 167 Logging in, part 3 168 DAY_OF_WEEK, CVT_FROM_INTERNAL_TIME, and SPAWN 169 DAY_OF_WEEK and CVT_FROM_INTERNAL_TIME 170 LIB_SPAWN 171 CREPRC 172 CREPRC, Part 2 173 COPY 174 COPY, part 2 175 COPY, part 3 176 COPY, part 4 177 LIB_Get_Default_File_Protection and LIB_Substitute_Wildcards 178 CREATESTREAM, STREAMNAME, and Set_Contiguous 179 Help Files 180 LBR Services 181 LBR Services, Part 2 182 LIBRARY utility 183 LIBRARY utility, Part 2 184 FS Services 185 FS Services, Part 2 186 Implementing Help 187 HELP 188 HELP, Part 2 189 DMG_Get_Key and LIB_Put_Formatted_Output 190 LIBRARY utility, Part 3 191 Shutting Down UOS 192 SHUTDOWN 193 WAIT 194 SETIMR 195 WAITFR and Scheduling 196 REPLY, OPCOM, and Mailboxes 197 REPLY utility 198 Mailboxes 199 BRKTHRU 200 OPCOM 201 Mailbox Services 202 Mailboxes, Part 2 203 DEFINE 204 CRELNM 205 DISABLE 206 STOP 207 OPCCRASH and SHUTDOWN 208 APPEND 209 APPEND and CONTINUE Glossary/Index Downloads |
Shells and UCL All operating systems come with some sort of user interface (otherwise they'd be useless in most cases). These interfaces have had many names over the years: "CCP" (Console Command Processor) for CP/M, "RTS" (Run Time System) for RSTS/E, "Command Line" on MSDOS, and "bash" for Unix/Linux, as but a few examples. On RSTS/E and Unix, there were several different interfaces available, and on Unix these interfaces were called "shells". Imagine the kernel/executive as the yolk and white of an egg, and the user interface as the shell that surrounds it. Getting access to the inside requires going through the shell. Hopefully, in terms of software, this doesn't require breaking the shell! The term "shell" has come to be a general name for Operating System interfaces - at least the textual ones. On Mac OS and Windows, the shell is graphical and is called the "Desktop".In olden days, the shell was often built into the O/S. Even today, the windows shell is an integral part of the O/S - although not of the kernel. Frequently, the shell was a BASIC interpreter. This was the case with older versions of RSTS/E, for instance. This approach provides a powerful interface since the user could enter simple commands or write complex code to accomplish whatever task was at hand. This was also a popular approach for the original personal computers, including the TRS-80, Commodores, Apples, and Amigas, among others. While modern shells aren't BASIC interpreters, the importance of being abile to do some sort of programming in the shell was recognized. Thus, shells like bash and MSDOS included the ability to use variables and conditionals in addition to the essential commands and programs. Likewise, the VMS shell (DCL) is an advanced programming interface. Sometimes shells are called "scripting engines", especially if they can "run" files containing code recognized by the shell. This code is often referred to as a "script". The line between a "script" and a "program" (especially interpreted ones) is somewhat fuzzy, and some scripts can be "compiled" into stand-alone programs. The main difference is that a script is usually customized for some other software platform, as opposed to being more "general-purpose". Graphical User Interfaces (GUIs) tend to not include scripting - a scripting engine provides that capability. Textual interfaces are distinguished from GUIs by the name "command line" interfaces. Some even make a distinction between a "textual user interface" and a "command line interface". We won't make that distinction. What is the nature of a shell, besides providing some rudimentary programming ability and being a way for the user to interact with the system? From the perspective of the average user, the shell is the operating system. But, a shell is simply a program. On UOS, the only difference from any other program is that a shell can be set as the program to run when no other programs are running. That is, a user is always running a program whether he realizes it or not. This might seem inefficient - if the user is doing nothing, why should a program be running and using system resources? But, in fact, while waiting for user input, the shell will be in an "input wait state", which uses no CPU or RAM. When the user runs another program, the shell exits and passes control to the program. When that program ends, the operating system automatically starts up the shell.
UCL UCL is the name of the script as well as the name of the program that executes that script. The script is compatible with VMS's DCL. The basic features of UCL are:
Although UCL serves as an interactive interface, it also can take commands from a file. Such files are called "command files" (files with an extension of ".com", by default). In fact, UCL can take input from a terminal, a file, or any other input device. Nor is this capability unique to UCL, or shells in general. All processes have certain logical I/O devices defined for them:
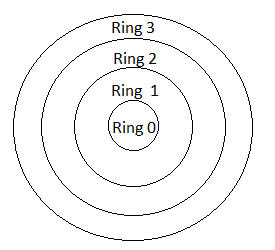
Rings Not surprisingly, the hardware-controlled elevated abilities have different names and implementations on different CPUs. For instance, most models of the PDP-11 had 3 modes: user, supervisor, and kernel. Modern Intel CPUs have four protection levels: kernel, system services, O/S extensions, and application. Other systems have other models. In general terms, these levels of access are referred to as "rings". Usually ring 0 is the most powerful level and is reserved for the kernel (or the executive in UOS), and higher rings indicate lower levels of access. Usually each ring has a completely separate set of register values, memory mapping, etc. so that it is impossible for an outer ring to access the context of a more inner ring, but inner rings can always access the context of a more outer ring. Not only does this mechanism allow protection from malicious code, it also protects the system from failure because of an application bug. Many times, a program with an errant pointer would crash the MSDOS operating system, which didn't use a ring model (because the original CPUs it ran on didn't have hardware protection). The scheme works because the only way for code at one ring to jump to code in a more inner ring is to use whatever mechanism the CPU provides for this, which turns control over to the code in the inner ring at a specific location. The following diagram illustrates the ring approach:
UOS uses a four-ring protection model, as follows:
One physical ring:
Two physical rings:
Three physical rings:
Four, or more, physical rings:
Thus, for an application program to do anything with the hardware, it must request the operation through the UOS executive. And to make a request to the executive, it must make a call to the innermost ring. However, since the actual mechanism may differ between platforms, applications that wish to be platform-independent must use a custom library that is included with each copy of UOS, which uses the mechanism appropriate for the hardware. This library is called "Starlet", and we will discuss it more in the future. One more issue for consideration is how we use the compiler that we are writing UOS in. All compilers include some form of interaction with the operating system - for I/O if for nothing else (a program that does no input or output and doesn't otherwise interact with the system is of no practical use). So, all compilers are implemented for a specific O/S. Since we are using a compiler that "targets" Windows, it won't work if we use the built-in file or heap support. Such an attempt would result in the program trying to send a request to Windows via the mechanism used by that O/S. But, since our programs will be running on UOS, they will have to send appropriate requests to UOS instead. We encountered this situation in the Init bootstrap and wrote a couple simple classes that simply made calls to the HAL rather than using certain built-in Pascal language features. At some future date, we will have a compiler that directly targets UOS, but in the meantime we will have to be careful to use Starlet to properly interact with the UOS executive. Note that this is not an issue that is unique to Delphi, or to Pascal. A Windows C++ compiler or Python interpreter are also tied to the Windows O/S. Even so-called "platform-independent" software such as C# and .net are tied to a given platform indirectly by the CLR (Common Language Runtime system). The CLR is simply a type of compiler, so it is subject to the same issue as any other compiler. In the case of an interpreter, the problem is simply moved from the compiled program code to the interpreter that runs it. In other words, you can't escape it - at some point a running program will need to interact with the O/S that it is running on. I will briefly acknowledge the existence of emulators, which map calls for one O/S to another. But the emulator has to be able to access the UOS API, so it doesn't solve the immediate problem. The subject of emulators is something that we will discuss in the future, because emulators do solve one class of problem - just not the one at hand. Now that we've laid the conceptual foundation, in the next article, we can discuss the UOS API and implement a file class to make use of it. Copyright © 2018 by Alan Conroy. This article may be copied in whole or in part as long as this copyright is included. |