|
1 Introduction 2 Ground Rules Building a File System 3 File Systems 4 File Content Data Structure 5 Allocation Cluster Manager 6 Exceptions and Emancipation 7 Base Classes, Testing, and More 8 File Meta Data 9 Native File Class 10 Our File System 11 Allocation Table 12 File System Support Code 13 Initializing the File System 14 Contiguous Files 15 Rebuilding the File System 16 Native File System Support Methods 17 Lookups, Wildcards, and Unicode, Oh My 18 Finishing the File System Class The Init Program 19 Hardware Abstraction and UOS Architecture 20 Init Command Mode 21 Using Our File System 22 Hardware and Device Lists 23 Fun with Stores: Partitions 24 Fun with Stores: RAID 25 Fun with Stores: RAM Disks 26 Init wrap-up The Executive 27 Overview of The Executive 28 Starting the Kernel 29 The Kernel 30 Making a Store Bootable 31 The MMC 32 The HMC 33 Loading the components 34 Using the File Processor 35 Symbols and the SSC 36 The File Processor and Device Management 37 The File Processor and File System Management 38 Finishing Executive Startup Users and Security 39 Introduction to Users and Security 40 More Fun With Stores: File Heaps 41 File Heaps, part 2 42 SysUAF 43 TUser 44 SysUAF API Terminal I/O 45 Shells and UCL 46 UOS API, the Application Side 47 UOS API, the Executive Side 48 I/O Devices 49 Streams 50 Terminal Output Filters 51 The TTerminal Class 52 Handles 53 Putting it All Together 54 Getting Terminal Input 55 QIO 56 Cooking Terminal Input 57 Putting it all together, part 2 58 Quotas and I/O UCL 59 UCL Basics 60 Symbol Substitution 61 Command execution 62 Command execution, part 2 63 Command Abbreviation 64 ASTs 65 Expressions, Part 1 66 Expressions, Part 2: Support code 67 Expressions, part 3: Parsing 68 SYS_GETJPIW and SYS_TRNLNM 69 Expressions, part 4: Evaluation UCL Lexical Functions 70 PROCESS_SCAN 71 PROCESS_SCAN, Part 2 72 TProcess updates 73 Unicode revisted 74 Lexical functions: F$CONTEXT 75 Lexical functions: F$PID 76 Lexical Functions: F$CUNITS 77 Lexical Functions: F$CVSI and F$CVUI 78 UOS Date and Time Formatting 79 Lexical Functions: F$CVTIME 80 LIB_CVTIME 81 Date/Time Contexts 82 SYS_GETTIM, LIB_Get_Timestamp, SYS_ASCTIM, and LIB_SYS_ASCTIM 83 Lexical Functions: F$DELTA_TIME 84 Lexical functions: F$DEVICE 85 SYS_DEVICE_SCAN 86 Lexical functions: F$DIRECTORY 87 Lexical functions: F$EDIT and F$ELEMENT 88 Lexical functions: F$ENVIRONMENT 89 SYS_GETUAI 90 Lexical functions: F$EXTRACT and F$IDENTIFIER 91 LIB_FAO and LIB_FAOL 92 LIB_FAO and LIB_FAOL, part 2 93 Lexical functions: F$FAO 94 File Processing Structures 95 Lexical functions: F$FILE_ATTRIBUTES 96 SYS_DISPLAY 97 Lexical functions: F$GETDVI 98 Parse_GetDVI 99 GetDVI 100 GetDVI, part 2 101 GetDVI, part 3 102 Lexical functions: F$GETJPI 103 GETJPI 104 Lexical functions: F$GETSYI 105 GETSYI 106 Lexical functions: F$INTEGER, F$LENGTH, F$LOCATE, and F$MATCH_WILD 107 Lexical function: F$PARSE 108 FILESCAN 109 SYS_PARSE 110 Lexical Functions: F$MODE, F$PRIVILEGE, and F$PROCESS 111 File Lookup Service 112 Lexical Functions: F$SEARCH 113 SYS_SEARCH 114 F$SETPRV and SYS_SETPRV 115 Lexical Functions: F$STRING, F$TIME, and F$TYPE 116 More on symbols 117 Lexical Functions: F$TRNLNM 118 SYS_TRNLNM, Part 2 119 Lexical functions: F$UNIQUE, F$USER, and F$VERIFY 120 Lexical functions: F$MESSAGE 121 TUOS_File_Wrapper 122 OPEN, CLOSE, and READ system services UCL Commands 123 WRITE 124 Symbol assignment 125 The @ command 126 @ and EXIT 127 CRELNT system service 128 DELLNT system service 129 IF...THEN...ELSE 130 Comments, labels, and GOTO 131 GOSUB and RETURN 132 CALL, SUBROUTINE, and ENDSUBROUTINE 133 ON, SET {NO}ON, and error handling 134 INQUIRE 135 SYS_WRITE Service 136 OPEN 137 CLOSE 138 DELLNM system service 139 READ 140 Command Recall 141 RECALL 142 RUN 143 LIB_RUN 144 The Data Stream Interface 145 Preparing for execution 146 EOJ and LOGOUT 147 SYS_DELPROC and LIB_GET_FOREIGN CUSPs and utilities 148 The I/O Queue 149 Timers 150 Logging in, part one 151 Logging in, part 2 152 System configuration 153 SET NODE utility 154 UUI 155 SETTERM utility 156 SETTERM utility, part 2 157 SETTERM utility, part 3 158 AUTHORIZE utility 159 AUTHORIZE utility, UI 160 AUTHORIZE utility, Access Restrictions 161 AUTHORIZE utility, Part 4 162 AUTHORIZE utility, Reporting 163 AUTHORIZE utility, Part 6 164 Authentication 165 Hashlib 166 Authenticate, Part 7 167 Logging in, part 3 168 DAY_OF_WEEK, CVT_FROM_INTERNAL_TIME, and SPAWN 169 DAY_OF_WEEK and CVT_FROM_INTERNAL_TIME 170 LIB_SPAWN 171 CREPRC 172 CREPRC, Part 2 173 COPY 174 COPY, part 2 175 COPY, part 3 176 COPY, part 4 177 LIB_Get_Default_File_Protection and LIB_Substitute_Wildcards 178 CREATESTREAM, STREAMNAME, and Set_Contiguous 179 Help Files 180 LBR Services 181 LBR Services, Part 2 182 LIBRARY utility 183 LIBRARY utility, Part 2 184 FS Services 185 FS Services, Part 2 186 Implementing Help 187 HELP 188 HELP, Part 2 189 DMG_Get_Key and LIB_Put_Formatted_Output 190 LIBRARY utility, Part 3 191 Shutting Down UOS 192 SHUTDOWN 193 WAIT 194 SETIMR 195 WAITFR and Scheduling 196 REPLY, OPCOM, and Mailboxes 197 REPLY utility 198 Mailboxes 199 BRKTHRU 200 OPCOM Glossary/Index Downloads |
File Content Data Structure
Back in article 2, we briefly defined a "Store". This concept is fundamental to the design of the UOS File System, so let's review it. A store is anything that can store data. Here are the characteristics of stores, and examples of them:
* the ability to write data may be prevented if the device is set to read-only The reason for basing the UOS File System off of stores is that we can have the file system software work regardless of what physical device it is on. So long as a store interface is provided for the underlying hardware, the file system software can work with it and we don't need to concern ourselves with the differences between different storage mediums, within reason. This approach is useful because it means that we can easily manage a file system on a hard disk, in memory (a RAM disk), or in a file (a container file). All we need to do is provide the file system with an instance of a store for the device in question. RAM disks can be used to create very fast (but small) virtual disks in RAM. This can be used in place of (or in addition to) memory caching of slower hard disks or network disks. Caching happens automatically and is the default behavior, but the ability to create a RAM disk provides the user with a certain amount of flexibility. Container files are used to hold a lot of different data (files) within a single file. For UOS, we will use container files to create library files, for instance. But, that will have to wait until later.
Managed Stores A store is essentially an array of bytes. To support the largest available disks out there, we will use 64-bit pointers to access any point on the store. These pointers are simply integer offsets from the start of the store. So, a 1 Gb disk will have offsets 0 through 1,073,741,823. Thus, a 64-bit address range allows for a disk as large as 18 quintillion bytes (about 8 billion times the size of the largest hard disk today). All allocations on the store will return an offset that is on a minimum allocation size boundary, and we can verify that we have a valid pointer by making sure it is a multiple of the minimum allocation size. As long as we use valid pointers (that is, those returned from the store when an allocation is requested), and only read/write buffers that are multiples of the minimum allocation size, we will be accessing the store efficiently. On our 1 Gb hard disk, we would have 2,097,152 possible chunks which indicates the maximum number of file extents. Except that it doesn't. You see, a managed store needs to keep track of free and allocated space, which is typically done through an allocation table (a data structure that allows the store to manage the space). On this disk, the allocation table will take about 256Kb of space (512 chunks). This isn't much overhead on a small disk. But on a 1 Tb disk, there will be over 2 billion chunks and the allocation table will take up 256 Mb of space. As a percentage, that is a small amount of the total disk size, but 1/4 Gb for overhead is quite a lot (and there is other overhead we haven't talked about yet). One way to shrink the size of the allocation table is to increase the minimum allocation size. We call this the Cluster size, because we will cluster two or more chunks together on each allocation/deallocation. If we increase it to 1024, we halve the size of the allocation table to 128 Mb. We also reduce file fragments by about half. However, that also means that we waste 512 bytes per file, on average. With a clustersize of 512, we waste only an average of 256 bytes per file. The UOS File System can deal with any clustersize, although anything over 64K is likely to use up excessive amounts of RAM for I/O buffers. We will default to 512 as the clustersize for our File System stores, but allow the user to customize the cluster size for each device as they see fit. So, here is our abstract virtual store and managed store classes, descendants of which will be used for each type of hardware device supported by the UOS File System software:
First we define a couple data types, which are just synonyms for int64 (a signed 64-bit integer).
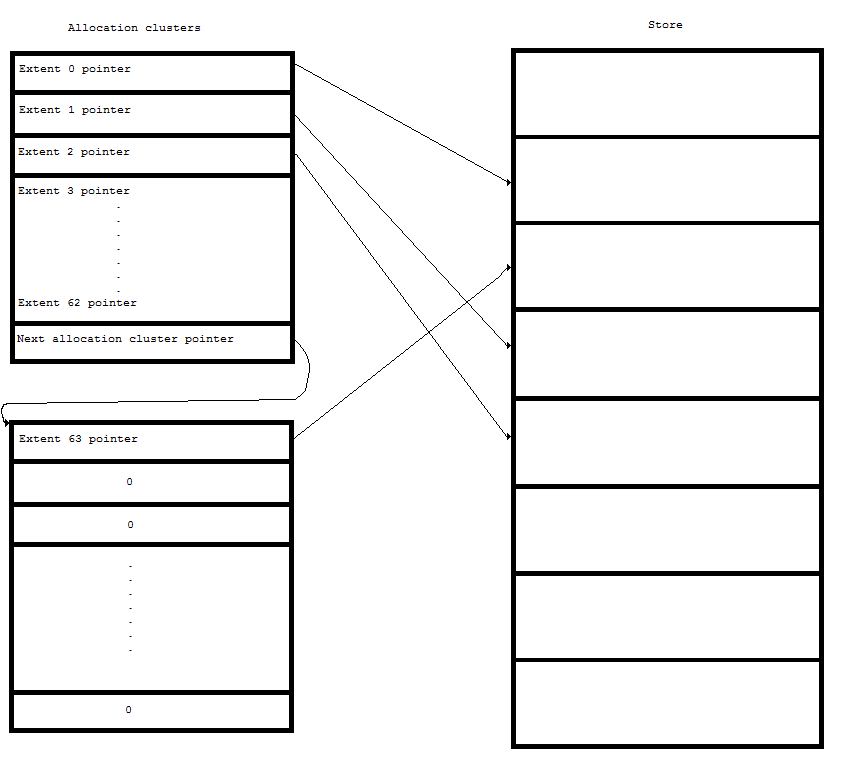
The managed store descends from the basic store, adding the allocation and deallocation features of a managed store. Now we are ready to look at the structures used to maintain the extents of our files. For a zero-length file, we actually don't need any pointers, but we'll ignore this situation for now. Since each extent of the file data can be anywhere on the store, since we don't know where the managed store will allocate the extent, we need a list of pointers to these extents - in essence, an array of pointers. But this array will need to be stored on the store as well, so that when UOS reboots, the array can be accessed and the file's data located. Since we will assume a minimum clustersize of 512 bytes, we can allocate 64 8-byte (64 bit) pointers. For a clustersize of 512, this can represent a file of up to 32Kb (64 x 512). What if we need a larger file? We will reserve the last pointer in a cluster as a pointer to another allocation cluster, with another 64 pointers. We can chain these allocation clusters together until we have enough for whatever file size we have. Unused pointers will be 0, and the last allocation cluster will end with a zero pointer since there are no more allocation clusters to link to. Here is a diagram of what a 32Kb file's allocation clusters might look like:
To access a specific location in the file, we simply take the desired file offset and divide it by the clustersize to determine the extent entry where that offset is located. We take the extent entry index and divide by 63 (the number of extent pointers in an allocation cluster) to get the allocation cluster in question. We follow the pointers at the end of each allocation cluster to get to the appropriate one. Then we take the extent entry index mod 63 to get the proper pointer offset within that allocation cluster. For instance, let's say that we have a request to access offset 25088 in the file. With a clustersize of 512, we divide 25088 by 512 to get extent index 49. We then divide that index by 63, to get allocation cluster 0. So, we need to access the first allocation cluster (cluster 0). 49 mod 63 gives us the pointer index 49 in this allocation cluster. That pointer is the location of that file position on the store. Although the overhead of the allocation clusters, in terms of storage space, amounts to a mere 1.5%, there is a potential performance problem associated with reading multiple allocation clusters while following the allocation links. One way to reduce the number of read operations required to reach the needed allocation cluster, is to give the files a larger cluster size. In such a case, more of the file would be represented by the extent pointers in each allocation cluster, reducing the total number of allocation clusters that are required for the file, and fewer read operations would be required to find the pointer to any specific file position. But we don't want to force all files to use a large cluster size just for the sake of one or two files. Therefore, UOS will allow each file to have its own cluster size, which must be a multiple of the store's cluster size. This will allow the user to balance the needs between space and performance efficiency according to his own needs. There are some system files that, for reasons of hardware requirements on Intel architectures, should have a clustersize of at least 4Kb, which we will discuss later. Suffice it to say that supporting different cluster sizes for each file provides a useful amount of flexibility, both for the user and for UOS itself. In the next few articles, we will write a file allocation class to manage the allocation clusters, and an extent store class to manage the file extents. |